


Automatyczna ocena jakości artykułów wielojęzycznej Wikipedii oraz identyfikacja istotnych źródeł jej informacji w różnych tematach

Wikipedia, jako największa i najbardziej popularna ogólnodostępna encyklopedia internetowa, odgrywa ważną rolę w globalnym dostępie do wiedzy i informacji. Ta platforma oferuje szybki dostęp do ogromnej ilości informacji na niemal każdy temat, co czyni ją cennym zasobem dla uczniów, studentów, nauczycieli i naukowców. Wikipedia umożliwia swobodny dostęp do informacji dla osób z różnych środowisk i regionów świata, przyczyniając się do zacierania różnic w dostępie do wiedzy. Obecnie ona posiada ponad 62 milionów artykułów w ponad 300 wersjach językowych.
Wolność edytowania Wikipedii jest zarówno jej wielkim atutem, jak i wyzwaniem. O ile wolność w dodawaniu i modyfikacji artykułów w tej encyklopedii umożliwia demokratyzację dostępu do wiedzy i wspiera globalną współpracę, o tyle wymaga także skutecznych mechanizmów kontroli jakości i moderacji. Wolność edytowania Wikipedii pozwala każdemu, niezależnie od poziomu wykształcenia czy pozycji społecznej, przyczynić się do budowania i rozwijania ogólnodostępnego zasobu wiedzy. Umożliwia to szeroki dostęp do tworzenia i udostępniania informacji. W porównaniu do tradycyjnych encyklopedii, Wikipedia może być aktualizowana niemal natychmiast po pojawieniu się nowych informacji czy wydarzeń. Jednak należy również wziąć pod uwagę, że ta wolność edytowania Wikipedii może prowadzić do celowego wprowadzania fałszywych informacji, usunięcia wartościowych treści lub innych form wandalizmu, co podważa wiarygodność i jakość encyklopedii. Ponadto, różne punkty widzenia i przekonania edytorów mogą prowadzić do stronniczości w artykułach, co może wpłynąć na neutralność i obiektywność prezentowanych informacji. Poza tym, częste edycje i rewizje mogą prowadzić do nadmiernej zmienności niektórych artykułów, co utrudnia utrzymanie spójności i jakości informacji. W związku z tym, zapewnienie wysokiej jakości wszystkich artykułów w różnych wersjach językowych w obliczu wolności edytowania stanowi znaczące wyzwanie.
Podczas seminarium dr Włodzimierz Lewoniewski omówił metody oraz narzędzia wykorzystywane do analizy i oceny treści w popularnej wielojęzycznej encyklopedii oraz sposobów identyfikacji i oceny źródeł informacji. W Katedrze Informatyki Ekonomicznej prowadzone są badania naukowe w obszarze tworzenia modeli do automatycznej oceny jakości artykułów Wikipedii w różnych językach. W ramach tych badań zostały opracowane setki miar. Niektóre z nich zostały zaimplementowane w ramach narzędzia WikiRank, które pozwala na ocenę jakości z użyciem miary syntetycznej jakości w skali ciągłej od 0 do 100. Rysunek poniżej przedstawia jeden z wykresów, przedstawionych podczas seminarium, gzie są pokazane wartości średnie jakości artykułów Wikipedii w różnych językach i tematach z użyciem tej miary (dane na luty 2024 roku, dostępna jest również wersja interaktywna tego wykresu):
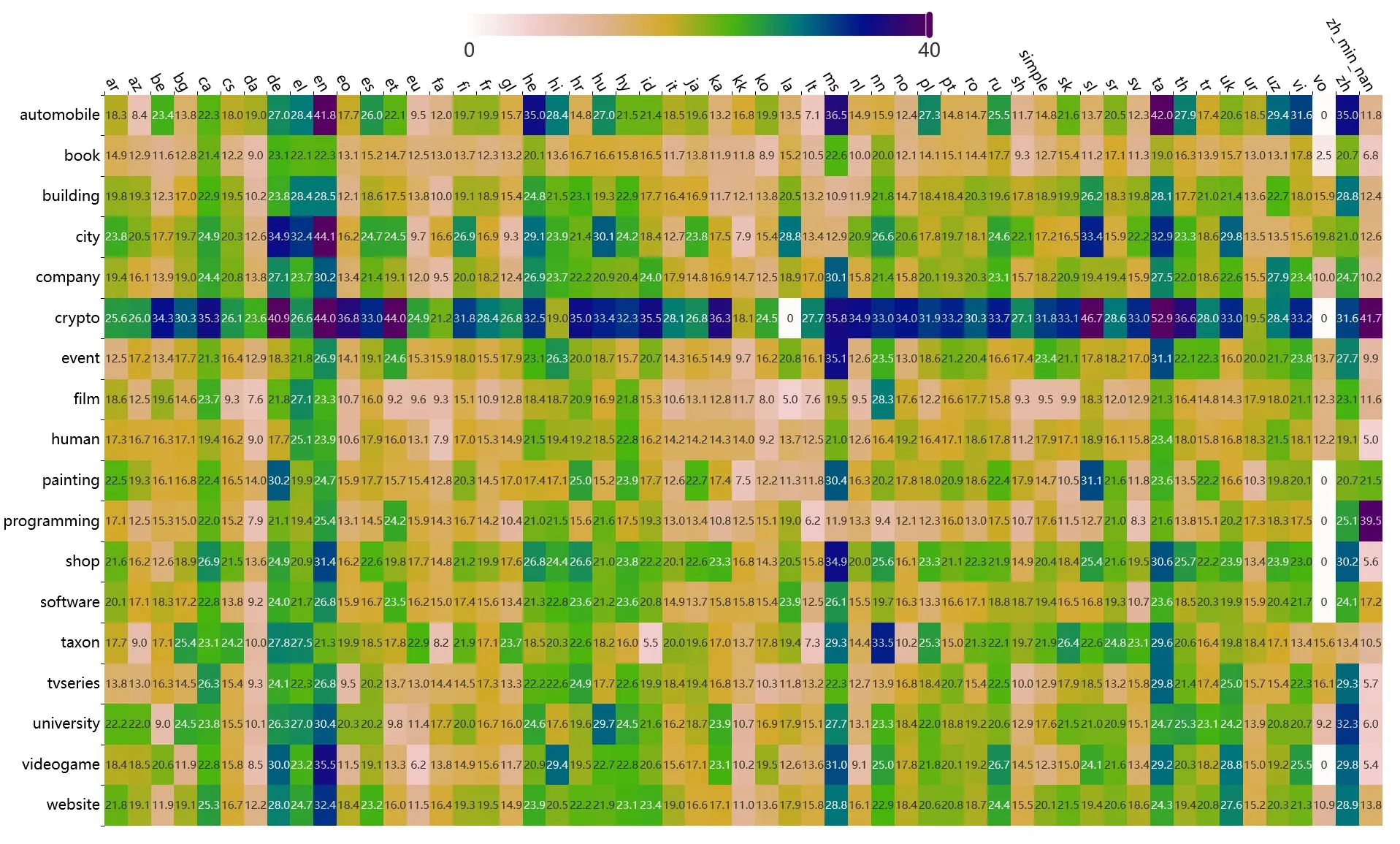
Prace naukowe również koncentrują się na analizie i ocenie wiarygodności źródeł informacji, które są cytowane w artykułach na Wikipedii. Znajduje się tam obecnie ponad 330 milionów przypisów (odnośników lub referencji) do różnorodnych źródeł, co umożliwia ocenę znaczenia poszczególnych stron internetowych jako dostawców informacji. Narzędzie BestRef to jeden z przykładów systemów, które analizują i oceniają miliony stron internetowych wykorzystywanych jako źródła informacji w Wikipedii.
Automatyczna ocena artykułów na Wikipedii ma na celu określenie, na ile treść tych artykułów spełnia różne kryteria jakości, takie jak kompletność, obiektywność, aktualność, wiarygodność cytowanych źródeł, poprawność stylistyczna. Jest to szczególnie ważne w kontekście wielojęzycznej natury Wikipedii, gdzie różnice językowe i kulturowe wprowadzają dodatkowe wyzwania. Techniki uczenia maszynowego, w tym klasyfikacja z nadzorem i bez nadzoru, służą do wykrywania wzorców jakościowych w oparciu o wcześniej oznaczone przykłady.
Projekty takie jak DBpedia i Wikidane, będące otwartymi semantycznymi bazami danych, odgrywają kluczową rolę w ekosystemie otwartych danych oraz Internetu semantycznego. Ułatwiają one dostęp do obszernych zbiorów informacji w sposób zorganizowany i semantycznie spójny, co czyni je bezcennymi zasobami dla badaczy i naukowców. Pozwalają one na przeprowadzanie zaawansowanych analiz w różnorodnych dziedzinach, od nauk społecznych po medycynę, otwierając nowe możliwości dla badań i innowacji. Podobnie jak Wikipedia, wspierają one przetwarzanie danych w wielu językach, co ma kluczowe znaczenie dla globalnego dostępu do informacji.
Poprawa jakości Wikipedii może również wpłynąć na jakość innych popularnych usług i narzędzi online. Na przykład, wyszukiwarki internetowe takie jak Google czy Bing wykorzystują informacje z Wikipedii do tworzenia „pudełek wiedzy”, które dostarczają użytkownikom krótkie streszczenia i kluczowe informacje na temat poszukiwanych haseł. Te podsumowania często opierają się na treściach z Wikipedii, oferując szybki dostęp do skondensowanych informacji. Ponadto, narzędzia wykorzystujące generatywną sztuczną inteligencję, jak ChatGPT, korzystają z danych Wikipedii w swoich procesach uczenia, co pozwala na generowanie dokładniejszych i bardziej zróżnicowanych treści.
Seminarium Instytutu Informatyki i Ekonomii Ilościowej odbyło się w dniu 16 lutego 2024 roku.