


Analiza neutralności Wikipedii z wykorzystaniem sztucznej inteligencji
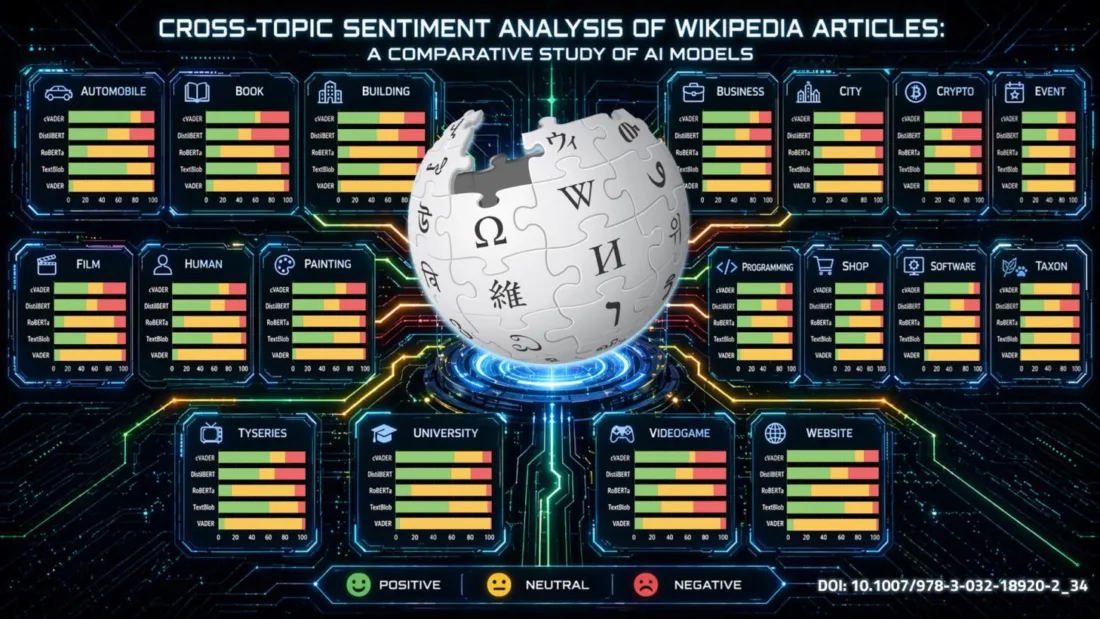
Artykuł autorstwa naszych naukowców pt. „Cross-Topic Sentiment Analysis of Wikipedia Articles: A Comparative Study of AI Models” został opublikowany. Praca koncentruje się na jednym z fundamentów Wikipedii – zasadzie neutralnego punktu widzenia, która zakłada bezstronne przedstawianie informacji. Publikacja ta pokazuje, jak nowoczesne metody AI mogą wspierać analizę jakości informacji w skali globalnej, jednocześnie ujawniając złożoność i wyzwania stojące za pojęciem „neutralności”.
W ramach badań zostały zastosowane różne modele do analizy wydźwięku: oparte na słownikach (TextBlob, VADER) oraz wykorzystujące architekturę transformerów (RoBERTa, DistilBERT). Analizie poddano około 7 milionów artykułów z anglojęzycznej Wikipedii, z których uprzednio zostały wyodrębnione fragmenty tekstowe, po czym artykuły sklasyfikowano tematycznie oraz przypisano do poszczególnych ocen jakości. Wyniki pokazały, że wydźwięk artykułów Wikipedii różni się w zależności od tematu, a wybór odpowiedniego modelu analizy ma istotny wpływ na końcową ocenę neutralności treści.
Autorzy zaproponowali również praktyczne ramy metodologiczne, które umożliwiają zastosowanie analizy wydźwięku do długich tekstów. Wyniki tej pracy mogą znaleźć zastosowanie m.in. w automatycznym monitorowaniu neutralności treści w otwartych źródłach wiedzy, wspieraniu redaktorów Wikipedii w identyfikowaniu potencjalnie stronniczych fragmentów tekstowych, rozwoju narzędzi do oceny jakości informacji w internecie.
Dodatkowo na platformie HuggingFace został udostępniony zbiór danych zawierający oceny wydźwięku przypisane przez poszczególne modele dla około 7 milionów artykułów Wikipedii. Zasób ten może stanowić cenne narzędzie dla badaczy i praktyków zainteresowanych analizą języka naturalnego oraz wykrywaniem stronniczości w tekstach. Szczegóły analizy można również znaleźć w materiałach dodatkowych.
Praca naukowa została zaprezentowana podczas prestiżowej konferencji IJCAI 2025. Autorzy publikacji: Włodzimierz Lewoniewski, Milena Stróżyna, Izabela Czumałowska, Aleksandra Wojewoda, Krzysztof Węcel. Publikacja jest dostępna pod numerem DOI: 10.1007/978-3-032-18920-2_34.
Publikacja powstała w ramach projektu OpenFact, finansowanego przez Narodowe Centrum Badań i Rozwoju w ramach programu INFOSTRATEG I „Zaawansowane technologie informacyjne, telekomunikacyjne i mechatroniczne”.